
For years, every backend software engineering team I worked with struggled with one unavoidable bottleneck: turning working local code into live production reality.
Running and debugging your code in the cloud was always slow, brittle, complex, and confusing. Often, it required total code rewrites into sophisticated frameworks to get the code to even run at all in the cloud environment.
Our new startup, PX Systems, is our attempt to finally fix this widespread pain. This month, we publicly unveiled a new command-line interface (the PX CLI) which can take working code in your programming language and get it running on freshly-provisioned cloud hardware in your cloud environment.
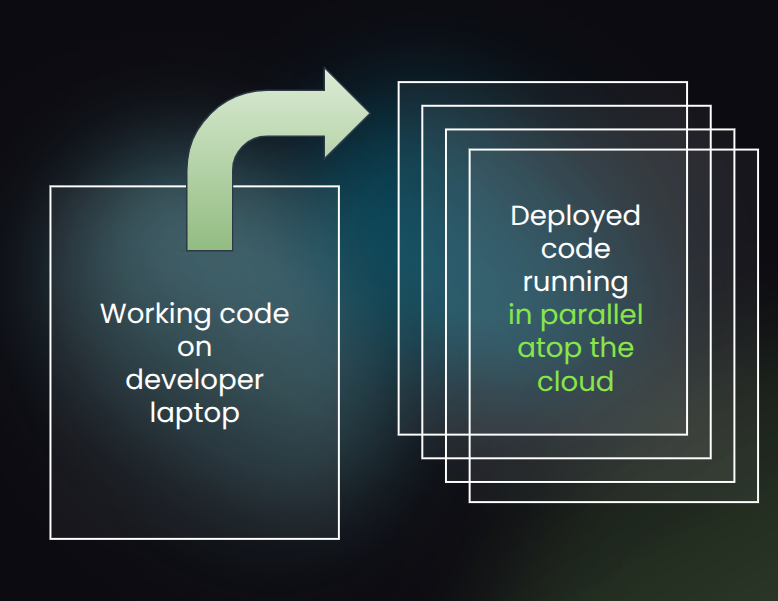
For years, we watched talented people struggle with this pain. The cloud had matured, but our day-to-day tools for wielding the cloud hadn’t.
This matters because so much of what we build today depends on the cloud, yet the gap from working software to deployed cloud system has only grown wider.
We aim to close that gap. And I’m happy to say that for the last few months I’ve been working with a small team of former colleagues on this, which is “startup #2” for me. Building this critical dev tools platform up from first principles has been fun. And I already see huge potential in what we’ve built. I’m ready to share a little bit about it publicly.
Our new company helps developers go from laptop to cloud cluster within seconds.

If you’re a backend engineer, read on. If not, you can still check out our website at https://px.app and share this post or the site with your team, where they can learn more.
The rest of this post will go into some of the technical details of how the PX CLI already works today, including how to build your first cluster and run your first cluster job — all the while using your favorite programming language and your existing cloud environment.
The last section of the post will cover how we plan to expand the PX CLI’s use cases over time, moving from one-off (batch) workloads to all other backend cloud cluster workloads.
Continue reading From laptop to cloud cluster within seconds (via the PX CLI)








