
My first computer did not have a web browser. But I remember using my first web browser (Mosaic) with some awe. It was the late 90’s and though the web was not nearly as beautiful or functional as it is now, it worked. It was clear — even to my young self — that there was something very special about it. The web had separated text from paper.
You see, before the web, we were already exploring alternative forms of text, in the context of the “desktop publishing” revolution, whose killer app — especially in media circles — was QuarkXPress. However, even desktop publishing still had a conceptual model of printed pages of text. The “output” of desktop publishing tools was almost always a paper printer. The “publishing” part of “desktop publishing” was “printing”. QuarkXpress and Adobe InDesign fought an epic battle to determine who could generate the best-looking paper, most efficiently.
In other words, digital media was a means, not an end. But with the web, it was an end in itself. The web changed that, and I think that’s what really got me hooked on the web in the early days. Once text had become unbound from paper, so much seemed possible. And indeed, so much was possible.
Today, text “unbound” from paper makes up a large part of our lives. Especially for creatives, like journalists and programmers. I think of text as the foundational element of web publishing.
So, what can journalists learn from programmers about text?
Programmers love “plain text”
Programmers were among the earliest adopters of unprinted text. “Teletype Terminals” were one of the first places text existed as an end in itself, rather than being transmitted via a paper medium.
Programmers write code, which is text, in programs called text editors, and many popular ones have been around for 4 or 5 decades. The foundational system technology of computing, UNIX, is based on the idea that a computer’s filesystem can be organized into a tree of “plain text files”. One of our most famous computer scientists took a detour from his career in algorithms analysis to invent a text transformation technology that is now used by most of the world’s academic research community to turn digital text into beautiful printed text.
While programmers have an obsession with text, journalists have an obsession with words. Text is a conveyor, not a thing being conveyed. Journalists have taken their words and adapted them to text forms necessary to reach their audiences over time.
Text into the newspaper column. Text into the magazine layout. Text on a publisher’s website. Text on their own website.
But I believe journalists should have a more comfortable relationship with text itself. It can be liberating to realize that text is an encoding of information, and that some of the encodings we have now are not only durable (that is, they’ll last a long time) but also flexible (that is, they can be repurposed for a variety of media forms).
So let us start with the basics: what, exactly, is “plain text”?
Plain text is “just keystrokes”
Send a text message to a friend, post a tweet, write an email, draft a letter in Microsoft Word. We all know that these have something in common.
If I wrote a tweet, I could send its contents to a friend as a text, I could forward it in an email, I could include it in my printed letter. That common thing is “plain text.” Plain text is a computer encoding of information that you could think of as “just keystrokes”.

An aside, in the above-pictured PDP-1 design, the keyboard was actually a typewriter that recorded keystrokes on paper punchcards! Also: the PDP-1 cost over $100,000 in 1960, or $950,000 in 2015 inflation-adjusted dollars. It was also the size of your living room!
People don’t often think about plain text that much, but programmers think about it a lot. Indeed, programmers needed to think about it in order to make computers text-capable, in the first place!
Plain text used to be an American thing
Huh? Well, digitized plain text originated on American computers built by American hardware designers and loaded up with software written by American programmers.
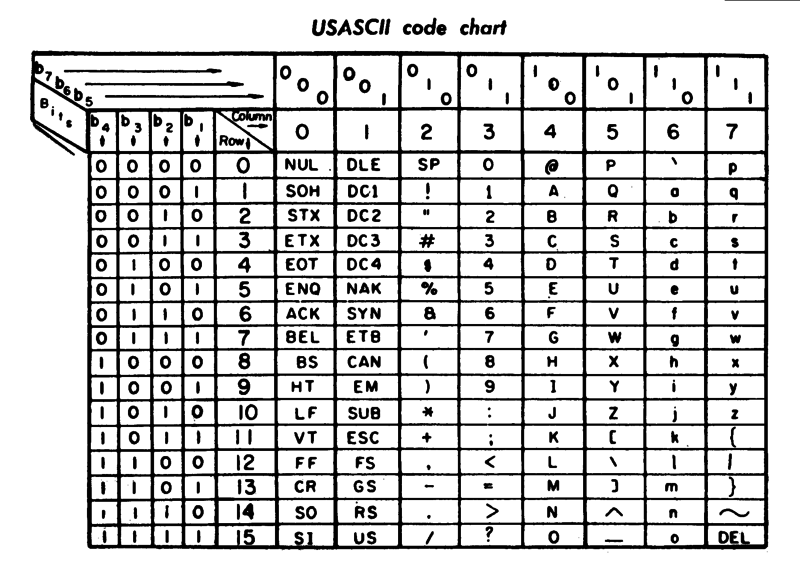
One of the first widespread text encodings was ASCII. That stands for “American Standard Code for Information Interchange”. I really love this name because though it’s a mouthful, it showcases just how essential plain text is. ASCII isn’t a “text encoding”, although that’s the way we think about it now. When ASCII was created, it was one of the first standards for information interchange. Plain text is cool because text represents information, and plain text represents information plainly.
The precursors to modern personal computing were developing in places like Bell Labs, where the UNIX operating system was born. Realizing that the value of plain text was not so much that it made it possible to digitally encode information, but also that it allowed for exchange of that information freely, this early computer operating system made the focus of its “core philosophy” around plain text files. “The Unix Way” is summarized as:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
Desktop computing and word processing
This essay opened with a discussion of desktop publishing, and how text remained bound to paper. The 80’s saw the rise of personal computing, desktop computing, and word processing as the “killer app”. But why? If in the 60’s and 70’s we already had UNIX and plain text (ASCII), why on earth did we need “special programs” to craft words?
The answer is two-fold:
- plain text represented information (aka content), but not style
- the primary output of a desktop computer’s word processing was still a paper printer — since there was no web, there was no good place to “digitally publish” text documents, plain or otherwise
The 80’s were, therefore, in a way, the dark ages of plain text. Though the UNIX and programmer communities regularly exchanged plain text artifacts, such as source code (and often via Sneakernet), the rest of the world was still hooked on paper. Outside of programming communities, computers were treated as a means to a paper end.
Microsoft, with the rise of Word as the market leader in word processing, conditioned consumers to the idea of proprietary document formats.
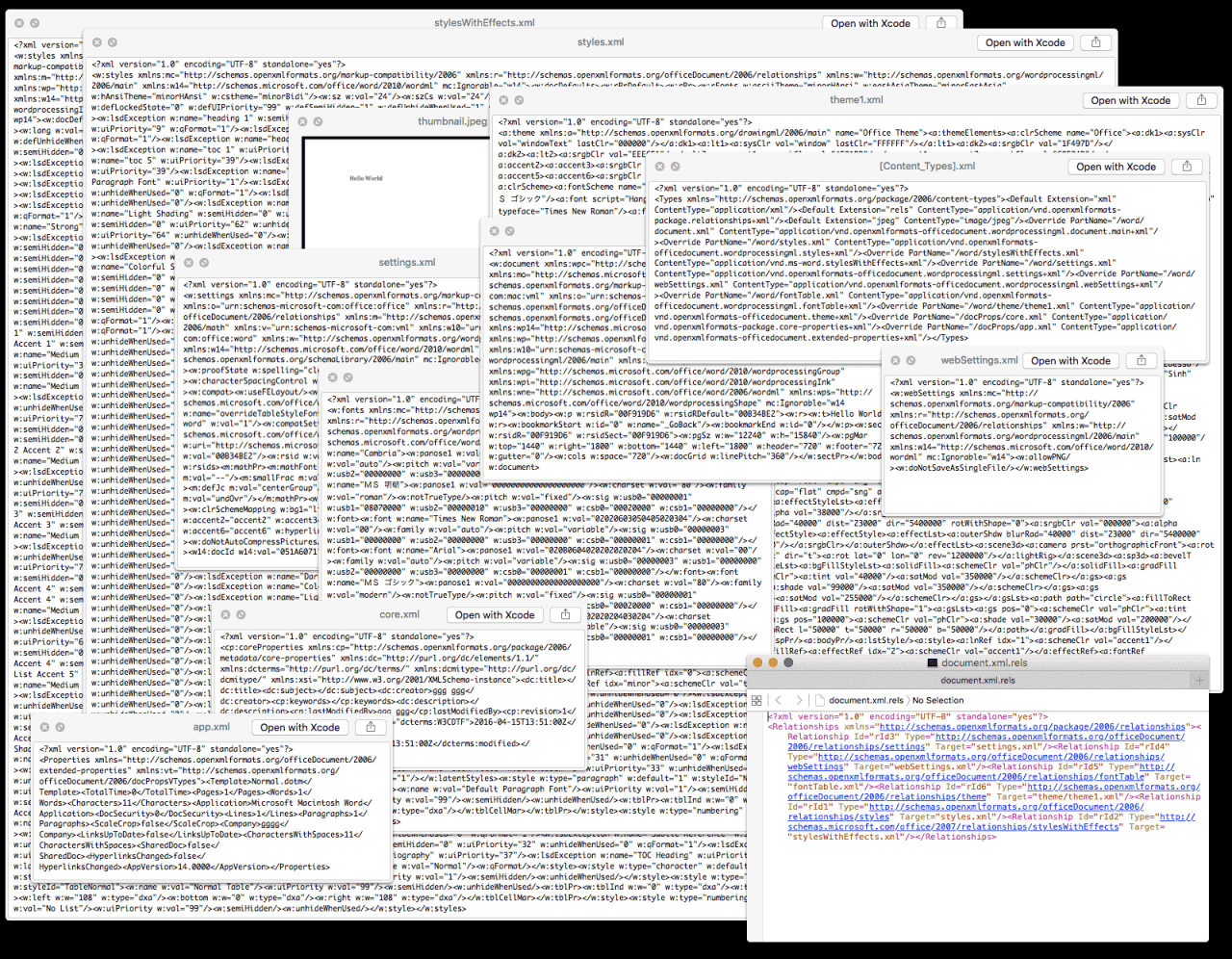
In the screenshot above, each window is a file containing nothing more than the words “Hello World.” The problem is, the file format is Microsoft Word. Thus, when we convert the binary file of Microsoft Word formatted storage back into “plain text”, we get a bunch of gibberish. This illustration is courtesy of ia Writer team.
The web arrives and plain text returns
When Tim Berners-Lee announced the World Wide Web in 1990, at its core was the notion of *hypertext.
In his original words:
HyperText is a way to link and access information of various kinds as a web of nodes in which the user can browse at will. It provides a single user-interface to large classes of information (reports, notes, databases, computer documentation and online help).
The web could not be bound to a specific proprietary format for its network effects to take hold. Instead, Berners-Lee developed something called HTML, which was essentially text with links, structure, and basic styles. We’ll describe HTML more later.
Computers may have become popular in America early, but it wasn’t long before they were everywhere, and information exchange became an international affair. The simultaneous rise of personal computing and the web assured this would happen.
This led to another standard, almost as plain as ASCII, but with more support for languages that were not just American English. This was UTF-8.
UTF-8 became especially popular on the web. Take a look at this graph showing the percentage of pages that were using ASCII vs UTF-8 encoding over time. The 2001 web was mostly ASCII, but the modern web is mostly UTF-8. This is because the web, much like personal computers, “went global” over time.
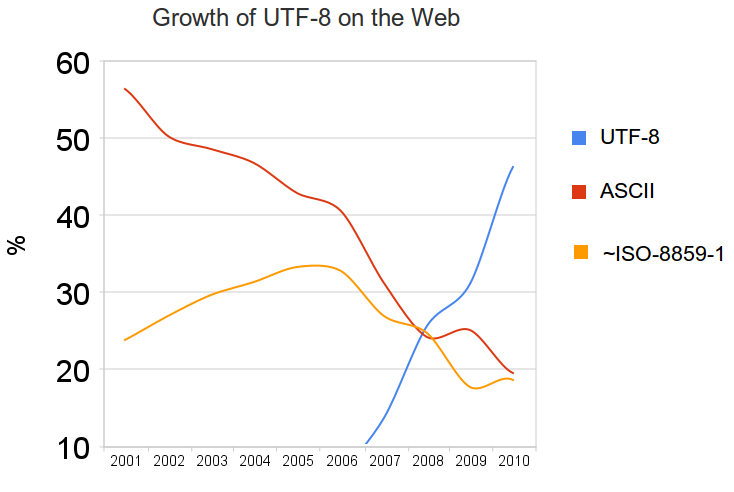
So, how badly did we need UTF-8? Pretty badly!
As English language speakers, we’re fortunate that our language can be represented in relatively few characters. But other languages of the world are not so economical with their information representation. For example, to write “hello, world!” in Greek before UTF-8 existed meant you had to “ASCII-ize” your language, which is quite the annoying experience. However, thanks to UTF-8, Greek characters such as “gamma” (Γ) and “epsilon” (ε) can be represented directly, rather than “transcoded” to the ASCII characters “G” and “e”.
- ASCII English: Hello, World!
- ASCII-ized Greek: Geia sou Kosme!
- UTF-8 Greek: Γειά σου Κόσμε!
This all becomes yet more complicated with the rise of Unicode, because the world, it turns out, is full of information interchange mechanisms — also known as alphabets and languages… to those of us who don’t live on the Internet.
The web brought us hypertext
The web adds two primary features to plain text: structure and links. It does this using a “markup language” called HTML, which itself uses plain text, but borrows certain characters (from ASCII!) to encode these structural aspects into the information document itself.
That is, when I say, this page links to Google, I am actually mixing two things: information content (“this page links to Google”) and information structure (an actual link to http://google.com.). The way to combine those two things together is HTML markup, which looks like this:
<a href="https://google.com">this page links to Google</a>
In this case, the "<a> tag" represents the structure, and the ASCII text inside represents the content. HTML lets us combine these two things, and web browsers, like Chrome, Firefox, and Safari, know how to “render” that HTML as a simple underlined clickable, which looks like this:
So, that’s markup — and there are lots of markup tags worth learning — but, what about style? Style is what gives every website its unique look-and-feel, and because programmers love plain text so much, they built web page styling as another separate layer from information content. It builds upon the structure of HTML text to instruct web browsers how to stylize your content. This system is called CSS. It wasn’t part of HTML originally — that’s part of the reason the early web was so, well, plain looking.
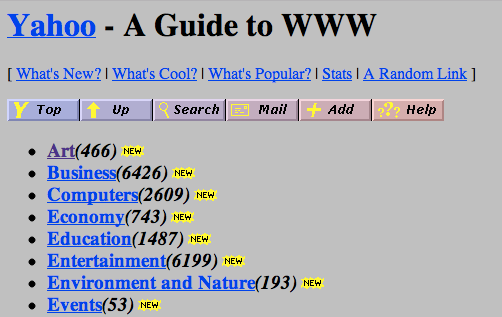
In the above Yahoo page, the gray background was because that was the “default background” in some browsers — websites didn’t have a way to customize their background color before CSS! Imagine that. CSS was developed (and standardized) relatively quickly thereafter. The first standard was released in 1996.
To further understand CSS, take this somewhat mind-bending article on Bloomberg.com, Paul Ford’s “What is Code?”. You should read it, it’s pretty good, and somewhat related to our discussion. But, you should also do something else that every web visitor should do more often. You should view its source code.
Follow the directions in that last link and you’ll be taken into your web browser’s “code viewer” — and you’ll be able to see exactly what the machine sees before it renders your pretty page in your browser. That’s HTML markup. If you search for a unique sentence of the article, such as “Many algorithms have their own pages on Wikipedia”, you’ll find examples of markup in the wild, for example:
Many algorithms have their own pages on Wikipedia. You can spend days poking around them in wonder. <a href="https://en.wikipedia.org/wiki/Euclidean_algorithm" target="_blank" rel="noopener">Euclid's algorithm</a>, for example, is the go-to specimen that shows up whenever anyone wants to wax on about algorithms, so why buck the trend?
Notice how this paragraph of text, though it embeds some structure and a link, does not say anything about style. How does your browser know to render it at, say, a size of 16 points, using the Tiempos web font? That’s a job for CSS. Somewhere on this page there is a link to a stylesheet that says something like this:
p {
font-size: 16px;
font-family: 'TiemposTextWeb-Regular', serif;
line-height: 20px;
}
And this plain text (yes, ASCII, once more!) is telling the browser, *every time you see a p tag, render it with these styles.
It’s text all the way down
So, all together now:
- ASCII represents (English language) information in a computer-friendly way, known as plain text.
- HTML is a trick that embeds structure and links into plain text, by hijacking certain characters, like
<and>, and making things called “tags”, like"<a>"and"</a>", that you can put around your text. - CSS is a trick that describes the style of certain structural elements of HTML, in another ASCII information encoding, using special characters like
"{"and"}"to mark off “style blocks” and":"to create"property: value"structures. - Browsers know how to render pages made up of this kind of HTML text in such a way that links are clickable, and paragraphs are spaced separately, and that CSS is applying the style rules, etc.
Programmers are pretty clever, eh?
HTML, especially, is meant to be written — and understood — by all literate users of the web. Using a web browser is only one half of web literacy, like knowing how to read essays but not how to write them.
Images and interactivity
Images and interactivity took awhile to add to the web because they are not nearly as simple and cheap as text to create, enhance, and transmit. But they did come eventually.
There is some lore around the tag, first suggested in 1999 by the creator of one of the original web browsers, Mosaic. Believe it or not, at the time, we weren’t even quite sure how to represent images on computers. The now-ubiquitous JPG, GIF, and PNG image formats were not even invented yet.
Now, I won’t veer too far off course or try to be too cute. Images are a very different kind of information than text, and their representation bears little resemblance to our earlier discussions of ASCII, UTF-8, and the like. You typically need something to generate an image for you, whether a digital camera, smartphone, or computer program. There is no such thing as a “plain image”. Or is there?
"ASCII Art" Mona Lisa
---------------------
o8%8888,
o88%8888888.
8'- -:8888b
8' 8888
d8.-=. ,==-.:888b
>8 `~` :`~’ d8888
88 ,88888
88b. `-~ ‘:88888
888b ~==~ .:88888
88888o--:’:::8888
`88888| :::’ 8888b
8888^^’ 8888
We have a different encoding mechanism for images, much less plain and much harder to grok for humans, which is broadly called raster graphics. Essentially, we encode the color information that would be present in a grid of “pixels”.
For the purpose of the web, though, images are a “done deal”. The image lives on your server somewhere; the HTML tag merely embeds it. CSS can help stylize it — for example, resizing, cropping, adding border effects.
Interactivity was the final trick of the web. During the famous “browser wars”, one of the key features that browser creators tried to nail was how to make web browsers not just information transmission programs, but also code transmission programs. That is, they wanted your browser to download code, and run it inside the browser. The early web really couldn’t do this, but the later web could, thanks to something called JavaScript.
JavaScript is yet another ASCII (well, UTF-8, really) representation of information. But this time, the information is code. For example, this HTML includes a piece of JavaScript embedded inside of it that will execute when the user clicks the link:
<a href="https://google.com" onclick="alert('hello')">
this page links to Google</a>
The part that says:
alert(‘hello’)
Is ASCII text that represents the notion of a JavaScript function, a rather annoying function that pops up a dialog inside your browser. Please, please, don’t use this function — it’s a regular favorite of spammers!
This just scratches the surface of what JavaScript can do. To be truly impressed, check out these example data visualizations, or revel at the interactivity inherent in a page like the New York Times story, “Is it better to rent or to buy?”, which uses JavaScript to render interactive data visualizations in the story itself.
For journalists, JavaScript can be understood well as the language of interactive journalism on the web (though it can do far more than that), whereas plain text (and HTML) is the language of written journalism.
Images have become important and are easy to create and to embed. Video and 360 images are all going through the “awkward growing pains” period that images once went through on the web, but they’ll start to feel native soon, too.
What about code?
Code is just another form of information, but it’s information about a process — typically an interactive process. It is programmer mastery over these elements of web code (HTML, CSS, and JavaScript) that enables all of the web applications you use every day. HTML is the basis of application content, CSS of style/presentation, and JavaScript of interactivity.
Programmers have also built other languages that are used outside of web browsers, that run in the background, on servers, sometimes even rendering HTML pages. One of my favorite programming languages is Python, and one of its most popular “web frameworks” — that is, a programming utility for automatically generating HTML pages — is called Django. The Django framework was actually started at a news company and built for journalists.
The creator of the Python programming language once said:
In reality, programming languages are how programmers express and communicate ideas — and the audience for those ideas is other programmers, not computers.
He went on to describe the early days of Google, the company:
The first version of Google was written in Python. The reason: Python was the right language to express the original ideas that Larry Page and Sergey Brin had about how to index the web and organize search results. And they could run their ideas on a computer, too!
So ponder this thought. Google, a web application you use every day, is itself a (very big) program, which is itself represented as code, probably some plain text representing the information of “how to index the web and organize search results”.
But Google is also a web site, a place you can go on the web, to access this program. The results you get from Google are web pages, themselves representations of information — for example, this web page about Google on Wikipedia, which can be easily found via an HTML link on a Google search page for, well, “Google”.
The reason Google can index the web so easily is because we represent information in a (relatively) plain and uniform way. Machines (“Web crawlers”) can read and understand web pages, no matter who publishes them.
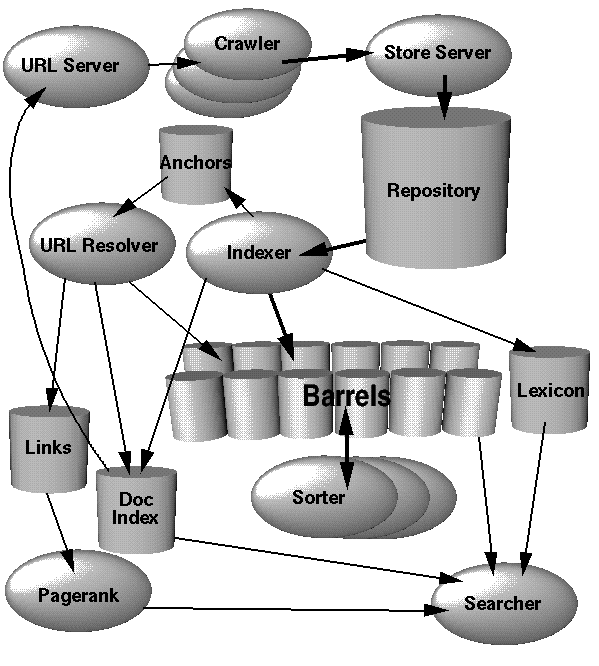
This strange diagram tried to convey the way Google worked. You can read the original Google paper to be reminded that, once upon a time, the creators of Google had to struggle to communicate what Google even was — and part of that was to make an HTML document describing Google, and post it on the web!
Gain a new respect for text
Text is still supreme on the web. As you’ve learned from this essay, this has something to do with programming, early programmers, and computer history. It is easier to process text, so programmers spend more time building tools for text.
One way to regain an appreciation for plain text is to adopt modern tools around it. One such tool that has taken off in the last few years is Markdown. I really love Markdown because it’s basically just a simplification of HTML that also illustrates that HTML is “just one way” of encoding structure and links into plain text.
How about me — do I still work with plain text? Yes, certainly! Though perhaps not hand-crafted HTML. Even though I am a programmer, I hardly ever write HTML by hand.
I actually wrote the original draft of this essay in Markdown, using a nice plain text authoring tool called iA Writer. You’re now viewing it as rendered HTML and CSS — and maybe a touch of JavaScript, too. That’s because there are good tools to convert Markdown to HTML, and because the JavaScript, CSS, and other styling details tends to get added later in the pipeline, for example, by a content management system like WordPress.
Now that you know a little more about plain text, you might start to become fond of Markdown, too. It’s very popular with writers of all kinds. Happy writing!