
A software engineer at LinkedIn has written a monster of a blog post about “The Log”, a building block for large-scale data systems. The concepts in this post are near and dear to my heart due to my work on precisely these kinds of problems at Parse.ly.
What is “a log”?
The log is similar to the list of all credits and debits and bank processes; a table is all the current account balances. If you have a log of changes, you can apply these changes in order to create the table capturing the current state. This table will record the latest state for each key (as of a particular log time). There is a sense in which the log is the more fundamental data structure: in addition to creating the original table you can also transform it to create all kinds of derived tables.
At Parse.ly, we just adopted Kafka widely in our backend to address just these use cases for data integration and real-time/historical analysis for the large-scale web analytics use case. Prior, we were using ZeroMQ, which is good, but Kafka is better for this use case.
We have always had a log-centric infrastructure, not born out of any understanding of theory, but simply of requirements. We knew that as a data analysis company, we needed to keep data as raw as possible in order to do derived analysis, and we knew that we needed to harden our data collection services and make it easy to prototype data aggregates atop them.
I also recently read Nathan Marz’s book (creator of Apache Storm), which proposes a similar “log-centric” architecture, though Marz calls it a “master dataset” and uses the fanciful term, “Lambda Architecture”. In his case, he describes that atop a “timestamped set of facts” (essentially, a log) you can build any historical / real-time aggregates of your data via dedicated “batch” and “speed” layers. There is a lot of overlap of thinking in that book and in this article.
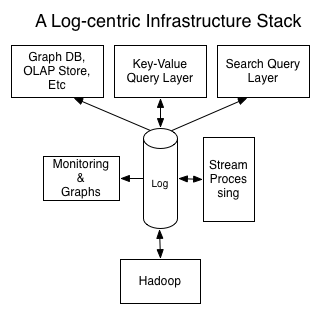
It’s great to see all the various threads of large-scale data analytics and integration coming together into a unified whole of similar theory and practice.
LinkedIn, for example, has almost no batch data collection at all. The majority of our data is either activity data or database changes, both of which occur continuously. In fact, when you think about any business, the underlying mechanics are almost always a continuous process—events happen in real-time, as Jack Bauer would tell us. When data is collected in batches, it is almost always due to some manual step or lack of digitization or is a historical relic left over from the automation of some non-digital process. Transmitting and reacting to data used to be very slow when the mechanics were mail and humans did the processing. A first pass at automation always retains the form of the original process, so this often lingers for a long time.
Production “batch” processing jobs that run daily are often effectively mimicking a kind of continuous computation with a window size of one day. The underlying data is, of course, always changing. […]
Interestingly, I also recently discovered that Kafka + Storm are widely deployed at Outbrain and Loggly. LinkedIn has its own stream processor, Samza, which relies directly upon Kafka. Meanwhile, AWS deployed a developer preview of Kinesis, based on the design of Kafka.
This all suggests to me that real-time stream processing atop log architectures has gone mainstream.
So, are stream processors a niche thing, only meant for analytics companies? LinkedIn’s engineers would argue that as the world is increasingly moving into having data feeds available in real-time, this will become more generalizable than the large-scale batch-oriented data flows (e.g. Hadoop, Map/Reduce) that came before. For context:
Seen in this light, it is easy to have a different view of stream processing: it is just processing which includes a notion of time in the underlying data being processed and does not require a static snapshot of the data so it can produce output at a user-controlled frequency instead of waiting for the “end” of the data set to be reached. In this sense, stream processing is a generalization of batch processing, and, given the prevalence of real-time data, a very important generalization.
So why has the traditional view of stream processing been as a niche application? I think the biggest reason is that a lack of real-time data collection made continuous processing something of an academic concern.
I once referred my work on Parse.ly as building a “content trading desk”. It was a weak connection, only realized in retrospect, that the kind of data I used to see when I worked on Wall Street and the kind I see in the media industry now has some overlap. Namely: “constantly updating time series”. LinkedIn also recognized that Wall Street was one of the only places where large-scale stream processing was happening, due to the availability of real-time market data:
I think the lack of real-time data collection is likely what doomed the commercial stream-processing systems. Their customers were still doing file-oriented, daily batch processing for ETL and data integration. Companies building stream processing systems focused on providing processing engines to attach to real-time data streams, but it turned out that at the time very few people actually had real-time data streams. Actually, very early at my career at LinkedIn, a company tried to sell us a very cool stream processing system, but since all our data was collected in hourly files at that time, the best application we could come up with was to pipe the hourly files into the stream system at the end of the hour! They noted that this was a fairly common problem. The exception actually proves the rule here: finance, the one domain where stream processing has met with some success, was exactly the area where real-time data streams were already the norm and processing had become the bottleneck.
Even in the presence of a healthy batch processing ecosystem, I think the actual applicability of stream processing as an infrastructure style is quite broad. I think it covers the gap in infrastructure between real-time request/response services and offline batch processing. For modern internet companies, I think around 25% of their code falls into this category.
It turns out that the log solves some of the most critical technical problems in stream processing, which I’ll describe, but the biggest problem that it solves is just making data available in real-time multi-subscriber data feeds.
The entire article is worth a read.