Real-time Streams & Logs¶
Andrew Montalenti, CTO

Agenda¶
- Parse.ly problem space
- Architecture evolution
- Organizing around logs (Kafka)
- Aggregating the stream (Storm)
- Real-time vs Batch tensions
Parse.ly problem space¶




Variety¶
- Audience data:
- visits
- sessions
- Engagement data:
- views / time spent
- social shares
- Crawl data:
- keywords / topics
- author / section / tag
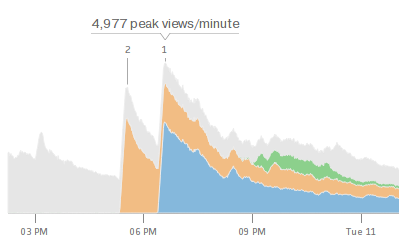
Velocity¶
- average post has <48-hour shelf life
- many posts get most traffic in first few hours
- major news events can cause bursty traffic
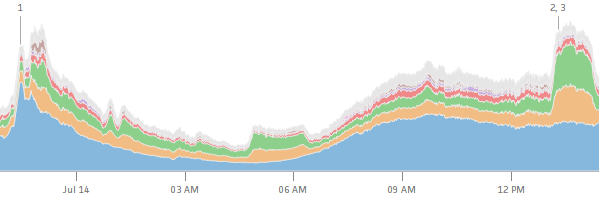
Volume¶
- top publishers write 1000’s of posts per day
- huge long tail of posts get traffic forever
- Parse.ly currently tracks 8 billion pageviews per month
- ... from over 250 million monthly unique browsers
Summary data¶
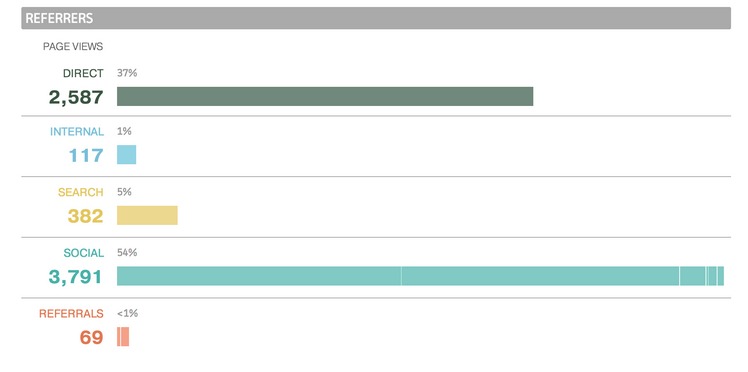
Ranked data¶
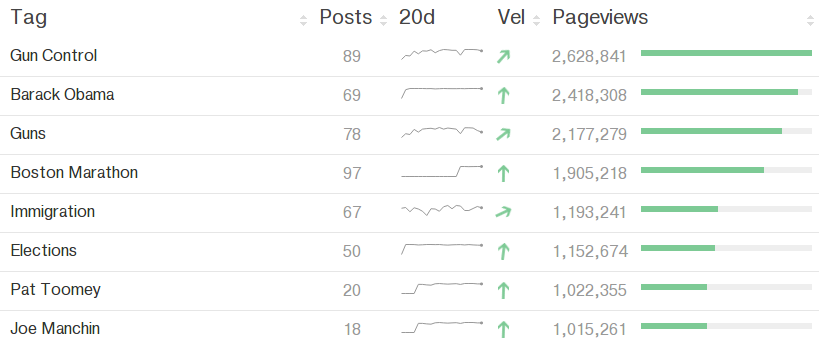
Benchmark data¶
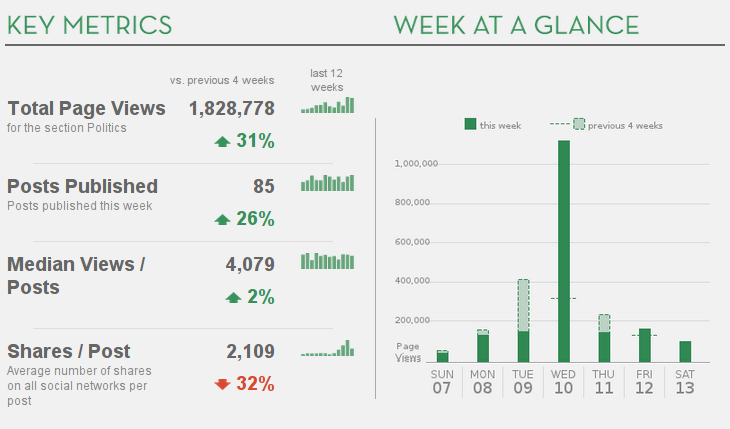
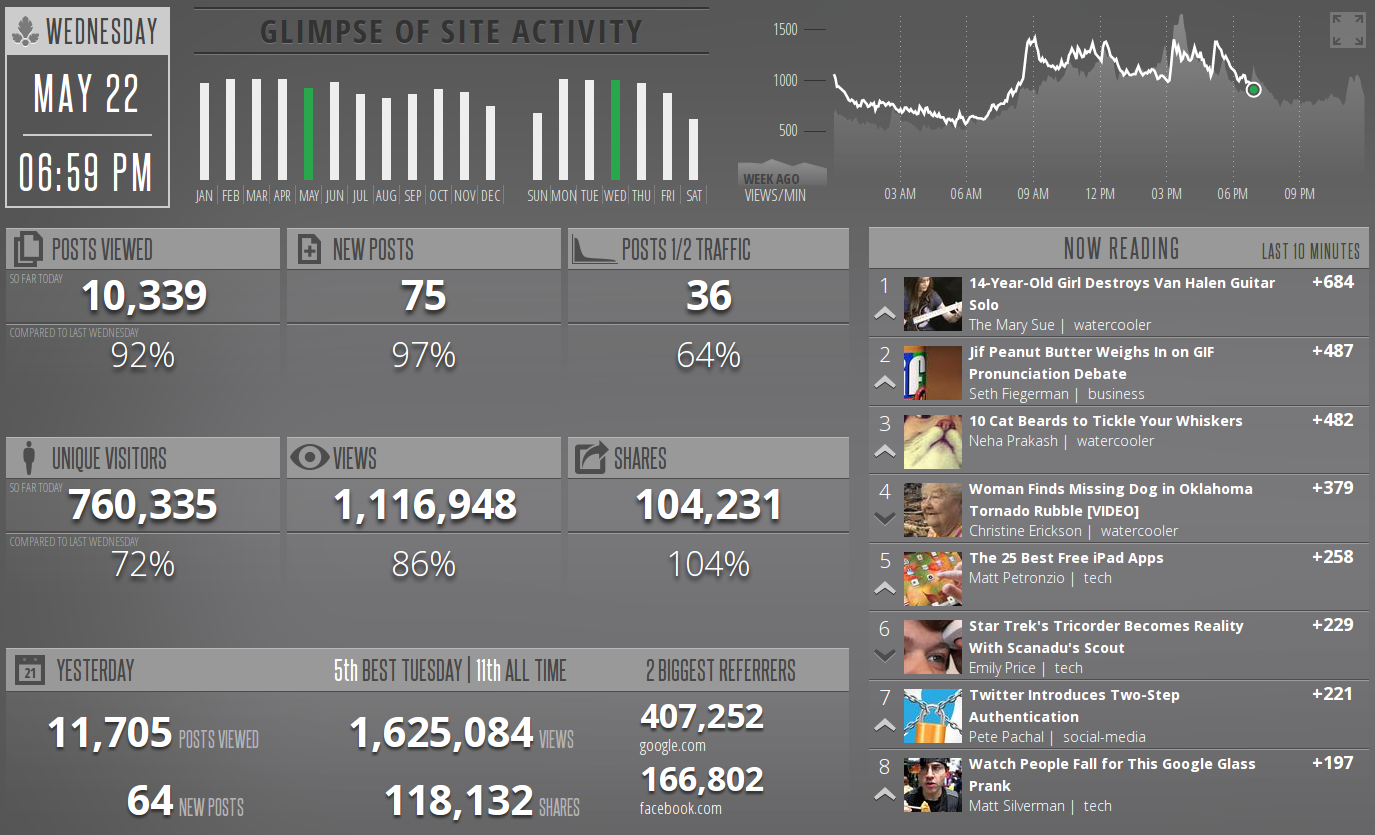
Information radiators¶
Architecture evolution¶
Stack Overview¶

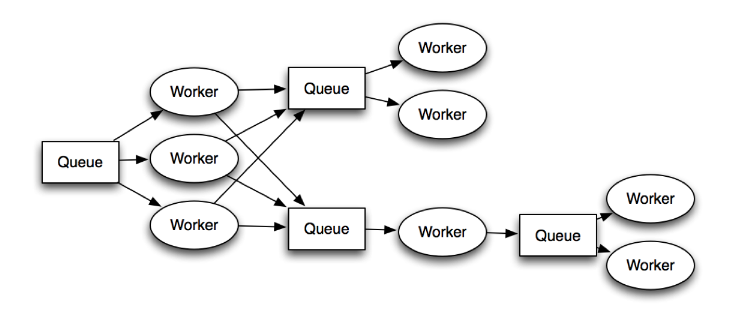
Queue problems¶
Traditional queues (e.g. RabbitMQ / Redis):
- not distributed / highly available at core
- not persistent (“overflows” easily)
- more consumers mean more queue server load
(Hint: ZeroMQ trades these problems for another: unreliability.)
Lots of moving parts¶
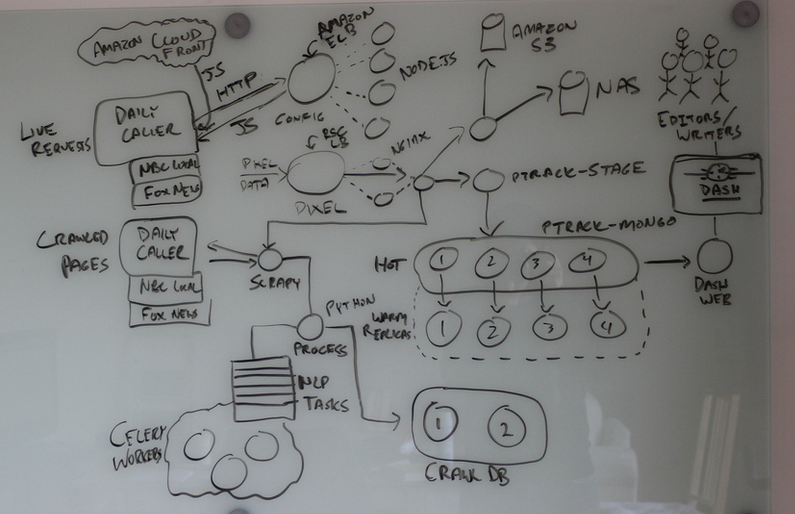
To add more features...¶
... we had to add more workers and queues!
Got harder and harder to develop on “the entire stack”.
More code devoted to ops, rather than business logic.
And, it had big hardware demands¶
Scaling Out: From 2010-2012, went from 3 to 80 nodes running in Rackspace Cloud.
Scaling Up: From 2012-2013, ran a custom data center with 1 terabyte of RAM.
Scaling In: From 2013-2014, started building support for more nuanced metrics.
And, data management challenges¶
Running multiple redundant data centers.
Need to ship real-time data everywhere.
Including data-identical production, staging, beta.
New schema designs and new DB technologies, too.
In short: it started to get messy¶

Organizing around logs¶
LinkedIn’s lattice problem¶
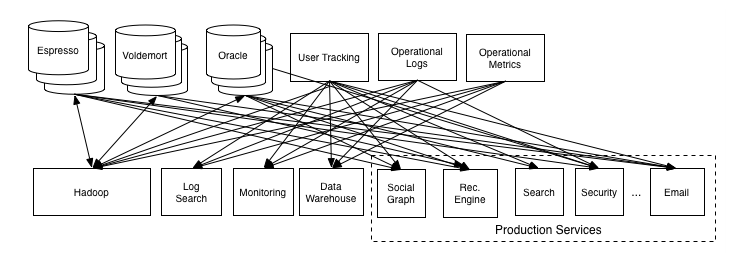
Enter the unified log¶
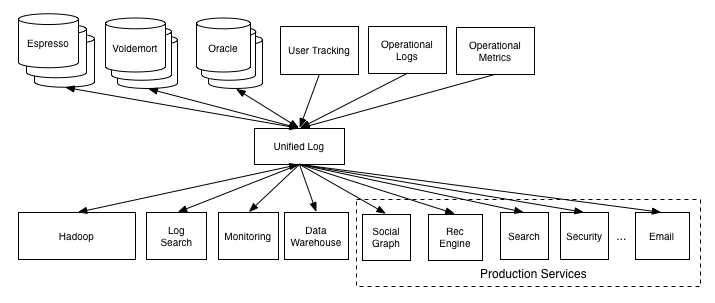
Log-centric is simpler¶
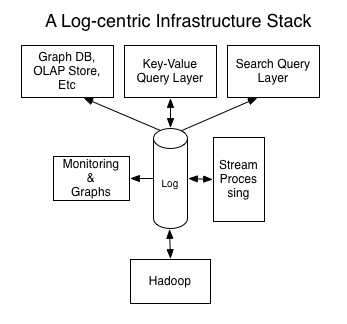
Parse.ly is log-centric, too¶
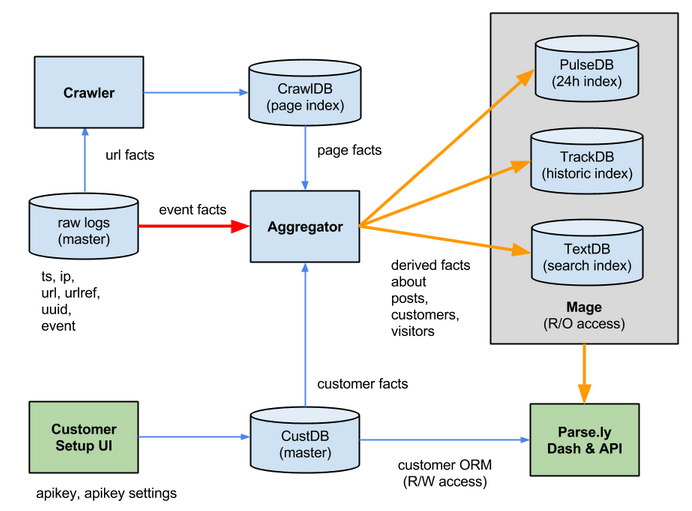
Introducing Kafka¶
| Feature | Description |
|---|---|
| Speed | 100’s of megabytes of reads/writes per sec from 1000’s of clients |
| Durability | Can use your entire disk to create a massive message backlog |
| Scalability | Cluster-oriented design allows for horizontal machine scaling |
| Availability | Cluster-oriented design allows for node failures without data loss (in 0.8+) |
| Multi-consumer | Many clients can read the same stream with no penalty |
Kafka concepts¶
| Concept | Description |
|---|---|
| Topic | A group of related messages (a stream) |
| Producer | Procs that publish msgs to stream |
| Consumer | Procs that subscribe to msgs from stream |
| Broker | An individual node in the Cluster |
| Cluster | An arrangement of Brokers & Zookeeper nodes |
| Offset | Coordinated state between Consumers and Brokers (in Zookeeper) |
Kafka layout¶
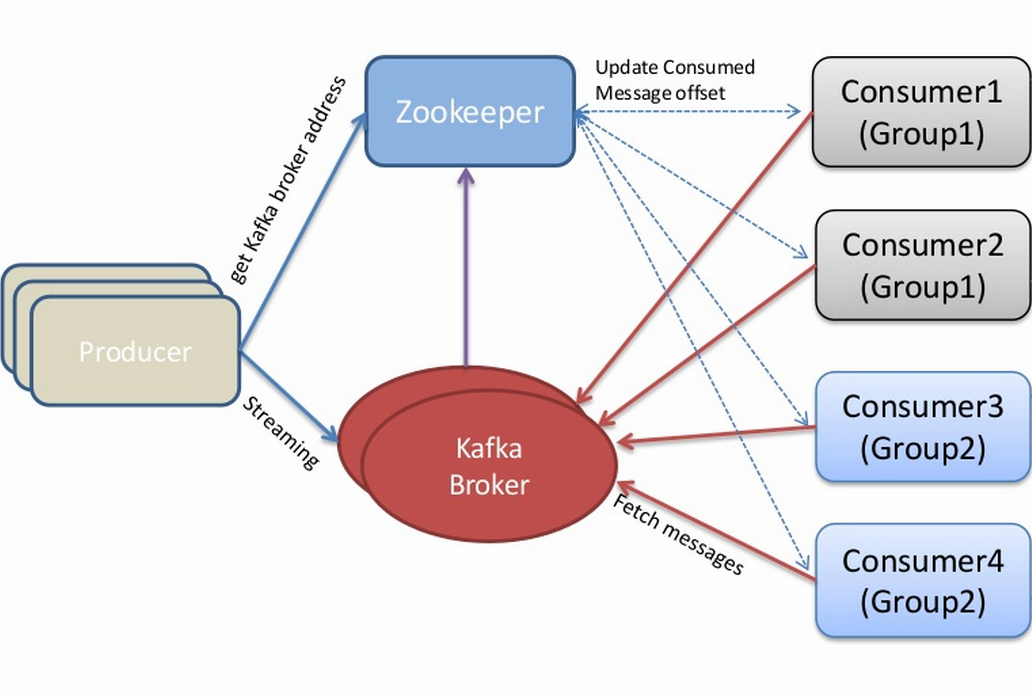
Kafka is a “distributed log”¶
Topics are logs, not queues.
Consumers read into offsets of the log.
Consumers do not “eat” messages.
Logs are maintained for a configurable period of time.
Messages can be “replayed”.
Consumers can share identical logs easily.
Multi-consumer¶
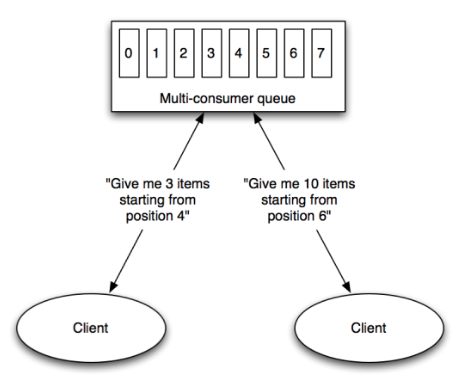
Even if Kafka’s availability and scalability story isn’t interesting to you, the multi-consumer story should be.
Queue problems, revisited¶
Traditional queues (e.g. RabbitMQ / Redis):
- not distributed / highly available at core
- not persistent (“overflows” easily)
- more consumers mean more queue server load
Kafka solves all of these problems.
Kafka in Python (1)¶
import logging
# generic Zookeeper library
from kazoo.client import KazooClient
# Parse.ly's open source Kafka client library
from samsa.cluster import Cluster
log = logging.getLogger('test_capture_pageviews')
def _connect_kafka():
zk = KazooClient()
zk.start()
cluster = Cluster(zk)
queue = cluster\
.topics['pixel_data']\
.subscribe('test_capture_pageviews')
return queue
Kafka in Python (2)¶
def pageview_stream():
queue = _connect_kafka()
count = 0
for msg in queue:
count += 1
if count % 1000 == 0:
# in this example, offsets are committed to
# Zookeeper every 1000 messages
queue.commit_offsets()
urlref, url, ts = parse_msg(msg)
yield urlref, url, ts
Aggregating the stream¶
So, what about Workers?¶
Kafka solves my Queue problem, but what about Workers?
How do I transform streams with streaming computation?
Worker data transforms¶
Even with a unified log, workers will proliferate data transformations.
These transformations often have complex dependencies:
- pixel request is cleaned
- referenced URL is crawled
- crawled URL’s text is analyzed by topic extractor
- repeated requests at identical URL rolled up by topic
- top performing topics are snapshotted for rankings
Workers and databases¶
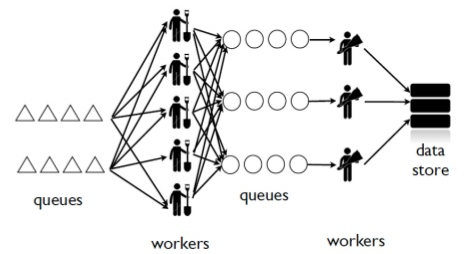
Worker problems¶
- no control for parallelism and load distribution
- no guaranteed processing for multi-stage pipelines
- no fault tolerance for individual stages
- difficult to do local / beta / staging environments
- dependencies between worker stages are unclear
Meanwhile, in Batch land...¶
... everything is peachy!
When I have all my data available, I can just run Map/Reduce jobs.
Problem solved.
We use Apache Pig, and I can get all the gurantees I need, and scale up on EMR.
... but, no ability to do this in real-time on the stream! :(
Introducing Storm¶
Storm is a distributed real-time computation system.
Hadoop provides a set of general primitives for doing batch processing.
Storm provides a set of general primitives for doing real-time computation.
Hadoop primitives¶
Durable Data Set, typically from S3.
HDFS used for inter-process communication.
Mappers & Reducers; Pig’s JobFlow is a DAG.
JobTracker & TaskTracker manage execution.
Tuneable parallelism + built-in fault tolerance.
Storm primitives¶
Streaming Data Set, typically from Kafka.
ZeroMQ used for inter-process communication.
Bolts & Spouts; Storm’s Topology is a DAG.
Nimbus & Workers manage execution.
Tuneable parallelism + built-in fault tolerance.
Storm features¶
| Feature | Description |
|---|---|
| Speed | 1,000,000 tuples per second per node, using Kyro and ZeroMQ |
| Fault Tolerance | Workers and Storm management daemons self-heal in face of failure |
| Parallelism | Tasks run on cluster w/ tuneable parallelism |
| Guaranteed Msgs | Tracks lineage of data tuples, providing an at-least-once guarantee |
| Easy Code Mgmt | Several versions of code in a cluster; multiple languages supported |
| Local Dev | Entire system can run in “local mode” for end-to-end testing |
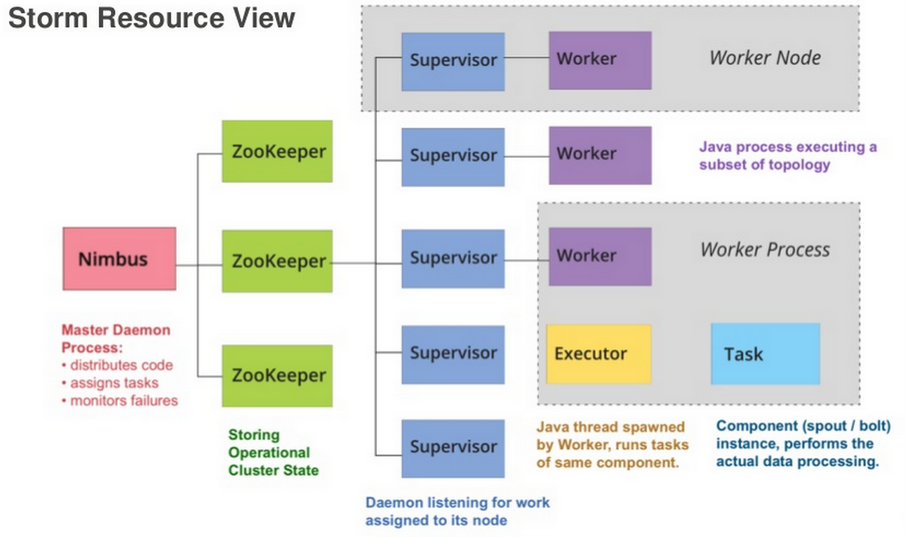
Storm core concepts¶
| Concept | Description |
|---|---|
| Stream | Unbounded sequence of data tuples with named fields |
| Spout | A source of a Stream of tuples; typically reading from Kafka |
| Bolt | Computation steps that consume Streams and emits new Streams |
| Grouping | Way of partitioning data fed to a Bolt; for example: by field, shuffle |
| Topology | Directed Acyclic Graph (DAG) describing Spouts, Bolts, & Groupings |
Wired Topology¶
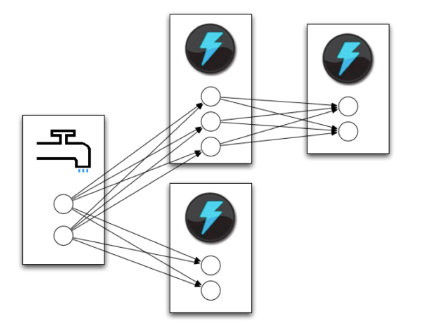
Storm cluster concepts¶
| Concept | Description |
|---|---|
| Tasks | The process/thread corresponding to a running Bolt/Spout in a cluster |
| Workers | The JVM process managing work for a given physical node in the cluster |
| Supervisor | The process monitoring the Worker processes on a single machine |
| Nimbus | Coordinates work among Workers/Supervisors; maintains cluster stats |
Running Cluster¶
Real-time vs Batch¶
Queries over data¶
Sample data file¶
A slice of Twitter clickstream (urls.json):
{"urlref": "http://t.co/1234",
"url": "http://theatlantic.com/1234",
"ts": "2014-01-01T08:01:000Z"}
{"urlref": "http://t.co/1234",
"url": "http://theatlantic.com/1234",
"ts": "2014-01-01T08:02:000Z"}
{"urlref": "http://t.co/1234",
"url": "http://theatlantic.com/1234",
"ts": "2014-01-01T08:03:000Z"}
{"urlref": "http://t.co/1234",
"url": "http://theatlantic.com/1234",
"ts": "2014-01-01T08:04:000Z"}
Pig example¶
Several billion such records (with much more variety) can be processed to find tweets driving high amounts of traffic to news publishers.
urls = LOAD 'urls.json'
USING JsonLoader(
'url:chararray, urlref:chararray, ts:chararray');
url_group = GROUP urls BY url;
url_count = FOREACH url_group
GENERATE group, COUNT_STAR(urls) as clicks;
DUMP url_count;
--> (http://t.co/1234, 4)
EMR cluster (lemur)¶
(defcluster pig-cluster
:master-instance-type "m1.large"
:slave-instance-type "m1.large"
:num-instances 2
:keypair "emr_jobs"
:enable-debugging? false
:bootstrap-action.1 [
"install-pig"
(s3-libs "/pig/pig-script")
["--base-path" (s3-libs "/pig/")
"--install-pig" "--pig-versions" "latest"]
]
:runtime-jar (s3-libs "/script-runner/script-runner.jar")
)
EMR Pig steps (lemur)¶
(defstep twitter-count-step
:args.positional [
(s3-libs "/pig/pig-script")
"--base-path" (s3-libs "/pig/")
"--pig-versions" "latest"
"--run-pig-script" "--args"
"-f" "s3://pystorm/url_counts.pig"
]
)
(fire! pig-cluster twitter-count-step)
Precomputed views¶
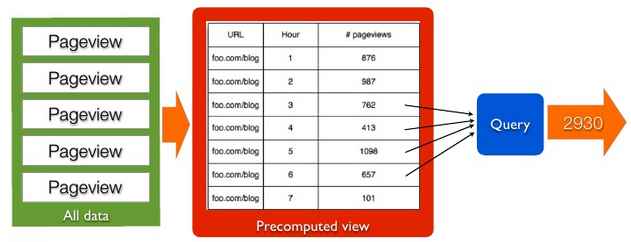
Twitter Click Spout (Storm)¶
{"twitter-click-spout"
(shell-spout-spec
;; Python Spout implementation:
;; - fetches tweets (e.g. from Kafka)
;; - emits (urlref, url, ts) tuples
["python" "spouts_twitter_click.py"]
;; Stream declaration:
["urlref" "url" "ts"]
)
}
Mock Spout in Python¶
import storm
import time
class TwitterClickSpout(storm.Spout):
def nextTuple(self):
urlref = "http://t.co/1234"
url = "http://theatlantic.com/1234"
ts = "2014-03-10T08:00:000Z"
storm.emit([urlref, url, ts])
time.sleep(0.1)
TwitterClickSpout().run()
Twitter Count Bolt (Storm)¶
{"twitter-count-bolt"
(shell-bolt-spec
;; Bolt input: Spout and field grouping on urlref
{"twitter-click-spout" ["urlref"]}
;; Python Bolt implementation:
;; - maintains a Counter of urlref
;; - increments as new clicks arrive
["python" "bolts_twitter_count.py"]
;; Emits latest click count for each tweet as new Stream
["twitter_link" "clicks"]
:p 4
)
}
Mock Bolt in Python¶
import storm
from collections import Counter
class TwitterCountBolt(storm.BasicBolt):
def initialize(self, conf, context):
self.counter = Counter()
def process(self, tup):
urlref, url, ts = tup.values
self.counter[urlref] += 1
# new count emitted to stream upon increment
storm.emit([urlref, self.counter[urlref]])
TwitterCountBolt().run()
Running a local cluster¶
(defn run-local! []
(let [cluster (LocalCluster.)]
;; submit the topology configured above
(.submitTopology cluster
;; topology name
"test-topology"
;; topology settings
{TOPOLOGY-DEBUG true}
;; topology configuration
(mk-topology))
;; sleep for 5 seconds before...
(Thread/sleep 5000)
;; shutting down the cluster
(.shutdown cluster)
)
)
Combining Batch & Real-Time¶
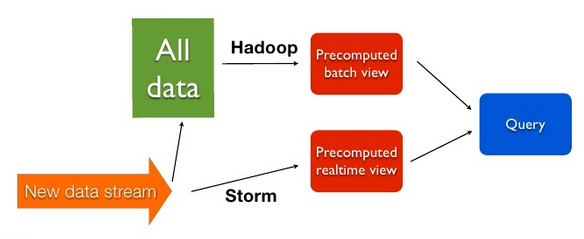
Marz’s Lambda Architecture¶
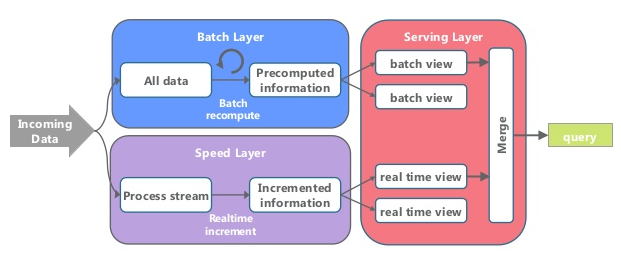
Eventual Accuracy¶
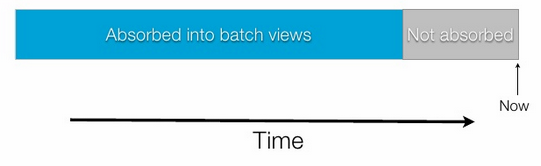
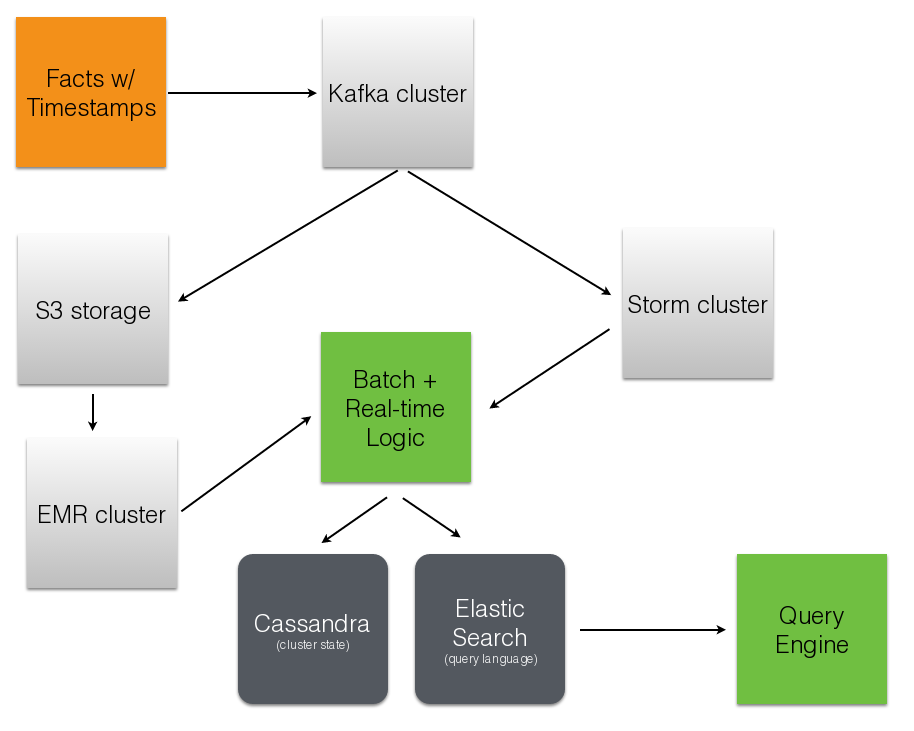
Parse.ly’s Stream Architecture¶
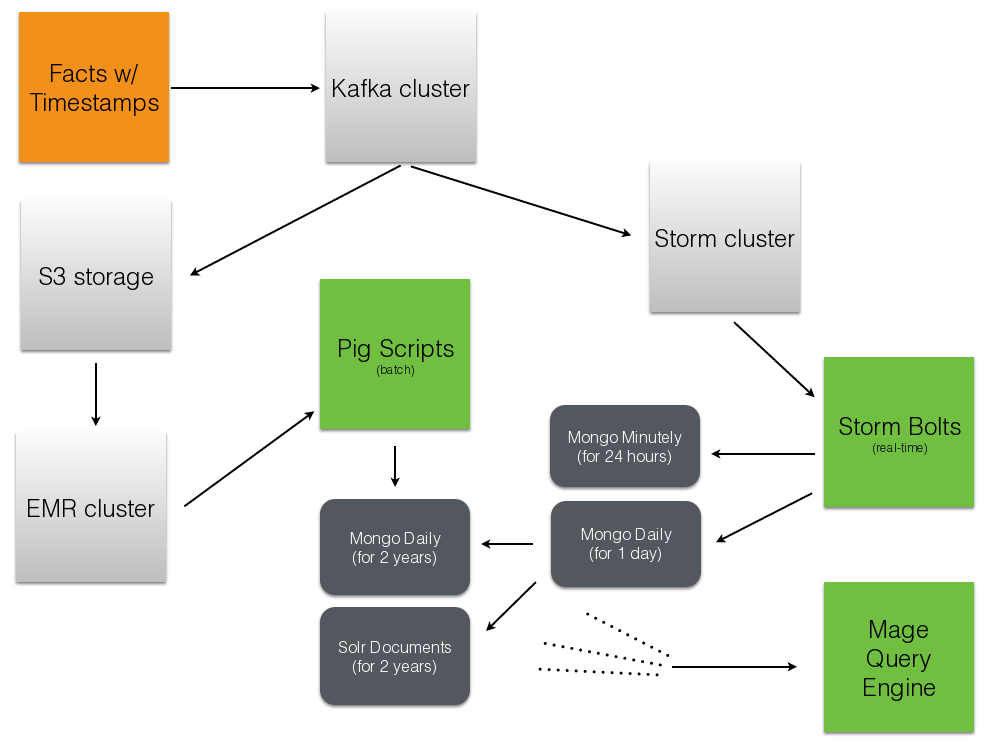
Where are we today? (1)¶
Tool Usage ELB + nginx scalable data collection across web S3 cheap, redundant storage of logs Scrapy customizable crawling & scraping MongoDB sharded, replicated historical data Redis real-time data; past 24h, minutely SolrCloud content indexing & trends Storm* real-time distributed task queue Kafka* multi-consumer data integration Pig* batch network data analysis
Where are we today? (2)¶
Component Current Ideal Real-time Storm + Redis Storm + Mongo Historical Pig/Storm + Mongo Evolved Mongo Schema Visitor Pig only Pig/Storm + Cassandra
Where are we today? (3)¶
Component Current Ideal Recommendations Queues + Workers Storm + Solr? Crawling Queues + Workers Storm + Scrapy? Pig Mgmt Pig + boto lemur? Storm Mgmt petrel pystorm?
Other Log-Centric Companies¶
Company Logs Workers Kafka* Samza Kafka Storm* Spotify Kafka Storm Wikipedia Kafka Storm Outbrain Kafka Storm LivePerson Kafka Storm Netflix Kafka ???
Alternative Approaches¶
Company Logs Workers Yahoo S4 S4 Amazon Kinesis ??? ??? Millwheel* Scribe* ??? UC Berkeley RDDs* Spark*
Python + Clojure¶
Opportunity for Python & Clojure to work together.
Python: core computations & DB persistence.
fabric: deployment & remote server management.
Clojure: interop with JVM infrastructure: Storm & Hadoop.
lein: manage Java’s classpath & packaging nightmare.
Python and JVM interop¶
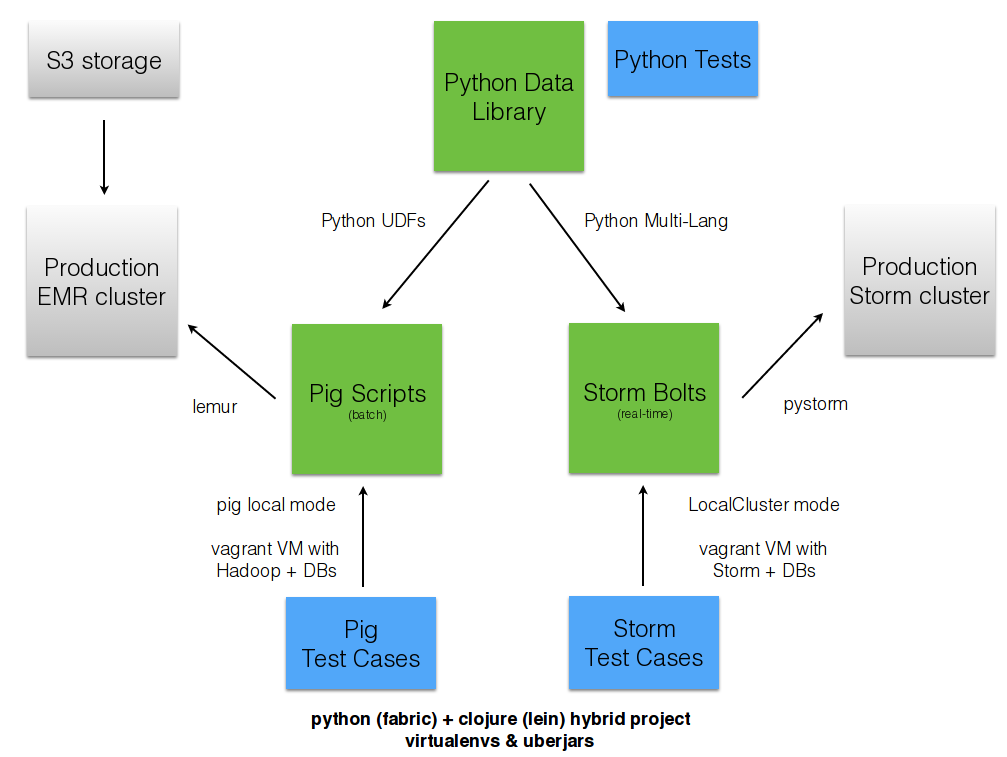
Conclusion¶
How times change...¶
Two years ago, EC2’s biggest memory box had 68GB of RAM & spinning disks. In early 2014, Amazon launched their i2 instance types:
Instance RAM SSD (!) Cores i2.8xlarge 244 GB 6.4 TB 32 i2.4xlarge 122 GB 3.2 TB 16 i2.2xlarge 61 GB 1.6 TB 8
- Each <$20/GB of RAM per month on-demand
- Big memory, performant CPU, and fast I/O: all three!
It’s the golden age of analytics.
What we’ve learned¶
- There is no silver bullet database technology.
- Especially for data problems with “the three V’s”.
- Log storage is very cheap, and getting cheaper.
- “Timestamped facts” is rawest form of data available.
- Organizing around logs is a wise decision.
What we’re learning¶
- Maybe databases aren’t databases, but are just indexes.
- Database isn’t endpoint for data, but a transformation.
- Duplicating data across databases isn’t evil...
- ... especially for query flexibility and latency ...
- ... but only if master data set makes rebuilds easy!
What is becoming clear¶
- There is a gap between Batch and Real-Time processing.
- But, it may not be there for long.
- Lots of active research going into making gap narrower.
- Pig + Storm work today, and offer powerful abstractions.
- Log-centric design (Kafka) will prep you for tomorrow.
Ideal data architecture¶